Overview

Our framework: (1) MS-TCN++ pretrained on human demonstrations is fine-tuned on robot data; (2) conformal prediction quantifies per-frame uncertainty; (3) uncertain segments are selectively queried by a VLM with edit-safe acceptance.
In assisted teleoperation for human-robot collaboration, accurate intention prediction is critical for enabling timely and reliable robotic assistance during long-horizon manipulation and assembly tasks. Robot teleoperation demonstrations are costly and hardware-limited, whereas human demonstrations are easier to collect and provide rich temporal structure. To address this challenge, we propose an uncertainty-aware human-to-robot intention prediction framework that combines: (1) hierarchical transfer learning, where MS-TCN++ is pretrained on human hand demonstrations and fine-tuned on limited robot teleoperation data; (2) a conformal prediction module that provides frame-level prediction sets with statistical coverage guarantees for reliable uncertainty quantification; and (3) VLM-guided segment correction, which selectively reviews low-confidence or temporally uncertain segments using visual and temporal context.
Experiments on robot assembly demonstrations with 22 action classes show that human-to-robot fine-tuning improves the robot test-set Edit score from 70.50 to 80.70 using only 16 robot demonstrations — a gain of 10.20 points over training from scratch. Edit-safe VLM correction preserves the Edit score while providing a safety net for uncertain segments. These results show that human demonstrations provide scalable pretraining data for robust, uncertainty-aware robot action segmentation.
Our framework: (1) MS-TCN++ pretrained on human demonstrations is fine-tuned on robot data; (2) conformal prediction quantifies per-frame uncertainty; (3) uncertain segments are selectively queried by a VLM with edit-safe acceptance.
Three components work together to produce reliable, uncertainty-calibrated action segmentation.
MS-TCN++ is pretrained on 51 UMI hand demonstrations encoding action transition priors, then fine-tuned on 16 ALOHA robot demonstrations. Both domains share a 22-class vocabulary and 192-dim X3D-M features, enabling complete weight transfer without architectural changes.
Temperature-scaled softmax probabilities are calibrated on a held-out split to produce prediction sets with finite-sample marginal coverage guarantees. Four variants are evaluated: standard (marginal), class-conditional, one-sided shrinkage, and two-sided shrinkage.
Segments flagged by low confidence or short duration are queried blind to the predicted label, preventing anchoring bias. Corrections are accepted only when they preserve or improve the video-level edit score, ensuring safe integration.
The 22×22 action transition matrix requires ~484 observed transitions to estimate reliably. Sixteen robot demonstrations provide only ~352 — insufficient to learn long-range assembly ordering. Pretraining on 51 human demonstrations encodes these priors and transfers them via fine-tuning.

51 training + 10 validation hand demonstrations of toy car assembly captured with an egocentric GoPro camera on a handheld UMI gripper.

40 teleoperated demonstrations yielding 80 synchronized streams (480×640, dual wrist cameras). Split: 16 train / 10 val / 8 test / 6 calibration demonstrations.
Evaluated on the ALOHA test set using frame accuracy, Edit score, and F1 at multiple overlap thresholds.
Transfer Learning
| Model | Edit ↑ | Acc % ↑ | F1 @10 ↑ | F1 @25 ↑ | F1 @50 ↑ |
|---|---|---|---|---|---|
| Hand-Only (zero-shot baseline) | 28.93 | 13.96 | — | — | — |
| Robot-Only (trained from scratch) | 70.50 | 40.22 | — | — | — |
| Human → Robot (ours) | 80.70 | 45.21 | 51.23 | 41.36 | 22.22 |
| Human → Robot + VLM (ours, best) | 80.70 | 46.42 | 51.97 | 41.81 | 22.98 |
Conformal Prediction
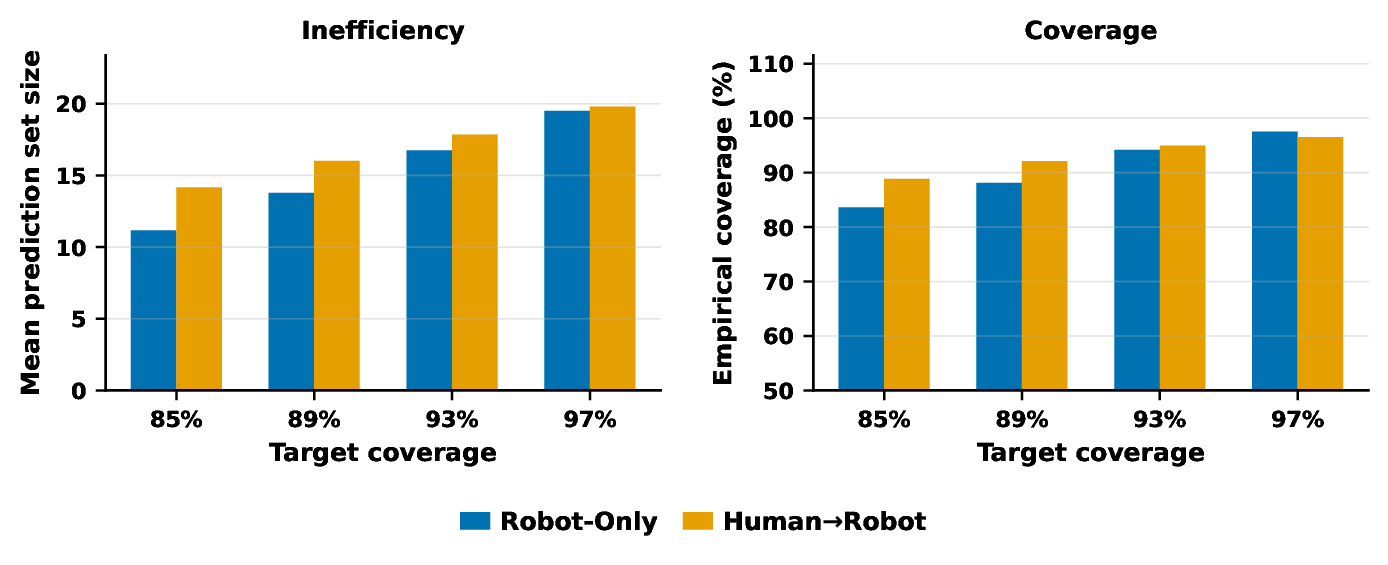
Standard CP
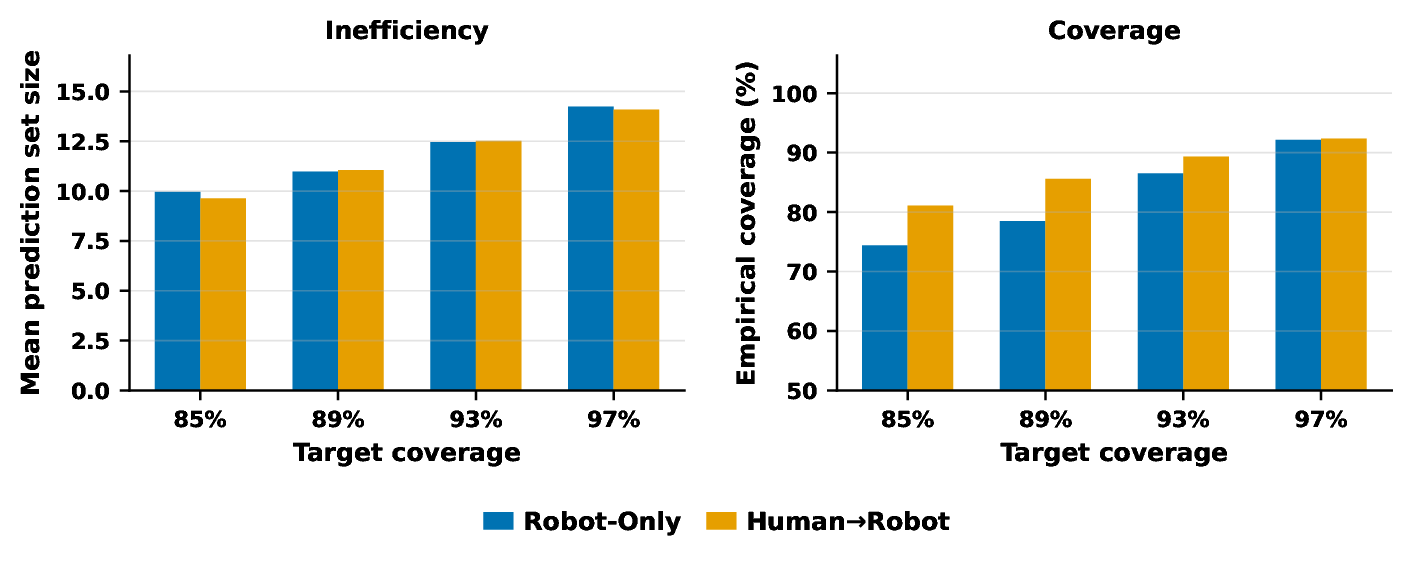
Regularized Class-Conditional CP
| CP Method | Target Level | Robot-Only Coverage | Human→Robot Coverage | Mean Set Size |
|---|---|---|---|---|
| Standard CP (marginal) | 93% | 94.2% | 95.0% | 16.8–17.8 |
| 97% | 97.5% | 96.5% | ~20 | |
| Class-Conditional CP (regularized) | 93% | 86.5% | 89.3% | ~12.5 |
| 97% | 92.1% | 92.3% | ~14 |
Segment-level predictions for teleoperated robot video
| Start | End | Duration | Ground Truth Action | Predicted Action | IoU | Result |
|---|---|---|---|---|---|---|
| 0 | 461 | 461 | pick up screw | pick up screw | 62.7% | correct |
| 461 | 896 | 435 | position screw on first wheel | position screw on first wheel | 63.3% | correct |
| 896 | 1015 | 119 | pick up first wheel | position screw on first wheel | 11.0% | incorrect |
| 1015 | 2159 | 1144 | position first wheel | position first wheel | 54.1% | correct |
| 2159 | 2757 | 598 | pick up electric screwdriver | position first wheel | 28.2% | incorrect |
| 2757 | 3581 | 824 | position screwdriver bit | position screwdriver bit | 46.4% | correct |
| 3581 | 3779 | 198 | screw first wheel with screwdriver | put down electric screwdriver | 59.9% | incorrect |
| 3779 | 3968 | 189 | put down electric screwdriver | pick up screw | 54.9% | incorrect |
16 correct / 22 segments | Human→Robot model | Video v220